对ElasticSearch(ES)性能优化实践
时间:2020-11-20 作者:安帝科技
1背景
1.1 基本配置
3个物理节点,单节点32G内存,4核,8TB机械硬盘,每个物理节点搭建一个Elasticsearch节点,Elasticsearch版本为6.2.4,采用管理工具为kibana、Elasticsearch-head和内部监控服务。
1.2 数据来源
数据为工业互联网安全态势感知平台内部处理的流式数据,Elasticsearch主要用于数据的存储和检索。
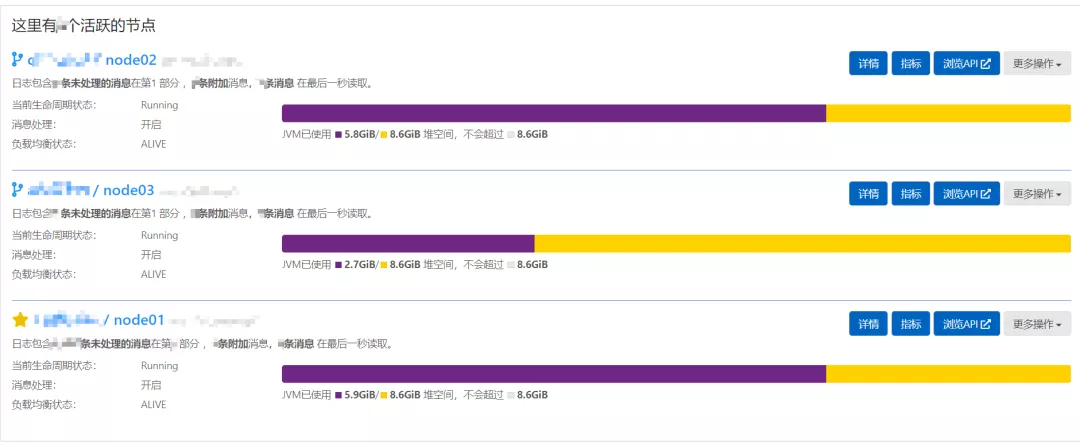
2发现问题
2.1 问题现象
由于公司业务的不断拓展和实施,安全态势感知平台每天处理的数据量在逐渐增加,Elasticsearch的写入性能达到瓶颈,数据不能及时写入到Elasticsearch中,积压在输出缓存中,还会传导至处理缓存,最终导致数据大量数据堆积在平台内部的kafka中,对数据的实时性和完整性都有影响。

2.2 查找原因
查看态势感知平台数据处理程序日志,经过排查,发现节点频繁抛出 RejectionException 异常和连接ES集群超时异常。命令查看ES任务状态:curl -u username:pwd ip:port/_cat/tasks/?v | more,发现大量的bulk任务处理时间过长,最高能达到10s之久,通常一次bulk应该控制在毫秒级别。查看线程池状态:curl -uusername:pwd-XGET “http://esip:port/_cat/thread_pool?v” | grep write,发现写入负载过高,出现大量拒绝。查看ES集群的CPU、内存使用率,CPU使用率偏低,内存使用率70%。查看ES的写入线程池大小为4,写入队列大小为500,已不能满足当前的写入场景。
3性能优化
通过以上分析,主要的性能瓶颈出现在数据写入这一块,所以着重处理这一部分,同时基于现有场景寻找其他的优化点,ES整体性能优化,大概可分为三个方向:
横向优化,优化写入模型。
纵向优化,提升单节点写入能力。
应用优化,探究业务节省资源的可能。
前期数据写入已经采用多线程bulk的写入方式,业务场景也基本确定,目前场景下,着眼于提升单节点性能。
3.1 增加索引缓存
indices.memory.index_buffer_size: 20%indices.memory.min_index_buffer_size: 512mb已经索引好的文档会先存放在内存缓存中,等待被写到到段(segment)中。缓存满的时候会触发段刷盘(吃i/o和cpu的操作)。默认最小缓存大小为48m,不太够,最大为堆内存的10%。对于大量写入的场景也显得有点小。
3.2 设置filedata cache大小
indices.fielddata.cache.size: 20%filedata cache的使用场景是一些聚合操作(包括排序),构建filedata cache是个相对昂贵的操作。所以尽量能让他保留在内存中。
3.3 设置节点之间的故障检测配置
discovery.zen.fd.ping_timeout: 120sdiscovery.zen.fd.ping_retries: 6discovery.zen.fd.ping_interval: 30s大数量写入的场景,会占用大量的网络带宽,很可能使节点之间的心跳超时。并且默认的心跳间隔也相对过于频繁(1s检测一次),此项配置将大大缓解节点间的超时问题。
3.4 设置段合并的线程数量
curl -XPUT ‘your-es-host:9200/index/_settings’ -d ‘{“index.merge.scheduler.max_thread_count” : 1}’段合并的计算量庞大,而且还要吃掉大量磁盘I/O。合并在后台定期操作,因为他们可能要很长时间才能完成,尤其是比较大的段。机械磁盘在并发I/O支持方面比较差,所以我们需要降低每个索引并发访问磁盘的线程数。这个设置允许max_thread_count + 2个线程同时进行磁盘操作,也就是设置为1允许三个线程。
3.5 设置index、merge、bulk、search的线程数和队列数
# Search poolthread_pool.search.size: 5thread_pool.search.queue_size: 500processors: 16# Bulk poolthread_pool.bulk.size: 16thread_pool.bulk.queue_size: 1000# Index poolthread_pool.index.size: 16thread_pool.index.queue_size: 1000这些配置能较大幅度提高ES集群性能,但非常占用计算机资源,要慎用,特别是processors这个参数!强制修改CPU核数,以突破写线程数限制,会大幅占用CPU资源,由于我们的ES集群独立部署在数据节点上,业务层没有其他应用和ES抢占CPU资源,CPU资源还算充裕。如果CPU资源使用率过高,则不建议盲目提高处理核数。
4优化结果
重启集群,配置生效后,写入拒绝量(write rejected)下降为0,ES集群bulk任务使用时间降至毫秒级别,总体来看消费的速度大于生产的速度,积压的历史数据逐渐被处理,经过一个夜晚时间,态势感知平台集群恢复正常状态。此次优化只针对我们当前遇到的ES性能瓶颈问题,其他的优化方面还有很多,例如在查询的性能和稳定性,集群的元数据变更性能等等方面。ES功能强大,拓展性强,在使用过程中我们需要整体分析,做针对性优化配置,方能使ES的性能使用最大化。







